AWS Route53 도메인 호스팅 영역에는 장애조치 레코드를 제공한다 (추가 - 기존 DNS에도 장애조치 레코드의 기능들은 제공하고있다.)
장애조치 레코드란 동일한 기능을 수행하는 2개 이상의 리소스가 있는 경우, 리소스들의 상태를 확인하고 정상적인 리소스만을 사용하여 DNS 쿼리에 응답하도록 제공하는 방식이다 (단 이 방법의 경우 라우팅이 변경되는 것으로 완전 무중단은 어렵다.)
본 포스팅에서는 Route53 장애조치 레코드를 생성하고 이를 테스트해본다. 이 때 failover가 잘 되었는지 확인하기 위해 Primary와 Secondary를 각각 다른 서비스와 연결시킨다 (일반적으로는 동일 서비스에 대해 장애조치를 구성함).
장애조치 레코드의 상태에따라 Route53은 다음과 같은 작업을 수행함을 테스트 전 알아둔다.

본 테스트를 수행하기 전 사전 조건은 다음과 같다.
- 2개 (Primary, Secondary)의 ELB (본 포스팅에서는 호스트 헤더에 따른 규칙도 별도 테스트하기위해 ALB를 사용하였으나, 전달만 필요한 서비스라면 NLB도 가능)
- Route53 호스팅 영역에 따른 ELB 설정 (예. 퍼블릭 호스팅 영역 - internet-faced ELB, 프라이빗 호스팅 영역 - internal ELB)
- 각 LoadBalancer와 HealthCheck가 success인 타겟 그룹
failover.example.com에 대하여 기본적으로 Primary ALB가 연결되어 서비스 중에 있다.
Primary 서비스 서버가 중지되어 Primary 타겟 그룹의 HealthCheck가 실패되면 Route53이 failover.example.com에 대한 DNS 쿼리 결과를 Secondary 레코드에 명시되어있는 Secondary ALB를 반환한다 (failover). 사용자는 DNS 쿼리 결과에따라 failover.example.com에 대하여 Secondary ALB 서비스로 접근하게된다.
구성 순서는 다음과 같다.
- 상태 검사용 CloudWatch Alarm 생성 (본 포스팅에서는 타겟 그룹의 정상 호스트 수 확인을 위해 별도의 Cloudwatch Alarm을 생성하였으나, Endpoint로 상태 검사가 가능함)
- Route53 상태 검사 생성
- Route53 장애조치 레코드 생성 (Primary, Secondary)
- 장애조치 테스트
1. 상태 검사용 CloudWatch Alarm 생성
Route53의 상태 검사는 CloudWatch Alarm, Endpoint (IP, Domain)를 바탕으로 진행된다. 본 테스트에는 이 중에서 CloudWatch Alarm을 생성하여, primary 타겟 그룹의 정상 호스트 수 1보다 작거나 수집되지 않을 때 경보가 발생하도록 설정하고 경보가 발생됨에따라 primary -> secondary로 failover 되는 것을 확인하겠다.
먼저 CloudWatch Alarm을 생성한다.
Metric: HealthyHostCount (타겟 그룹에서 모니터링하고있는 지표)
호스트 수가 1보다 작거나 해당 매트릭이 수집되지 않을 때 경보가 발생하도록 임계값을 설정한다.
- 지표 값 (HealthyHostCount)이 1보다 작을때 임계값 위반으로 간주
- Missing data treatment: Treat missing data as bad (누락 값은 임계값 위반으로 간주)
- 인스턴스가 중지되어 지표 수집이 되지않아도 이를 경보 대상으로 설정
CloudWatch alarm에는 경보시 동작 설정 (Notification, AutoScaling) 을 지원하나, 본 단계에서는 route53 failover 설정이 목적이므로 미설정 상태로 넘어간다.
2. Route53 상태 검사 생성
Route53 장애 조치 레코드는 같은 레코드 이름을 가진 2개의 레코드가 요구된다. Route53은 레코드에 설정된 대상 평가로 primary와 secondary 레코드 상태 기반으로 라우팅을 결정하는데, 레코드에 설정된 대상 평가 값이 Route53 상태 검사이다.
본 테스트에서는 하나의 CloudWatch Alarm (primary 서비스 호스트 헬스 체크)를 기반으로 Primary 레코드가 사용할 상태 평가, Secondary 레코드가 사용할 상태 평가 총 2개를 생성한다.
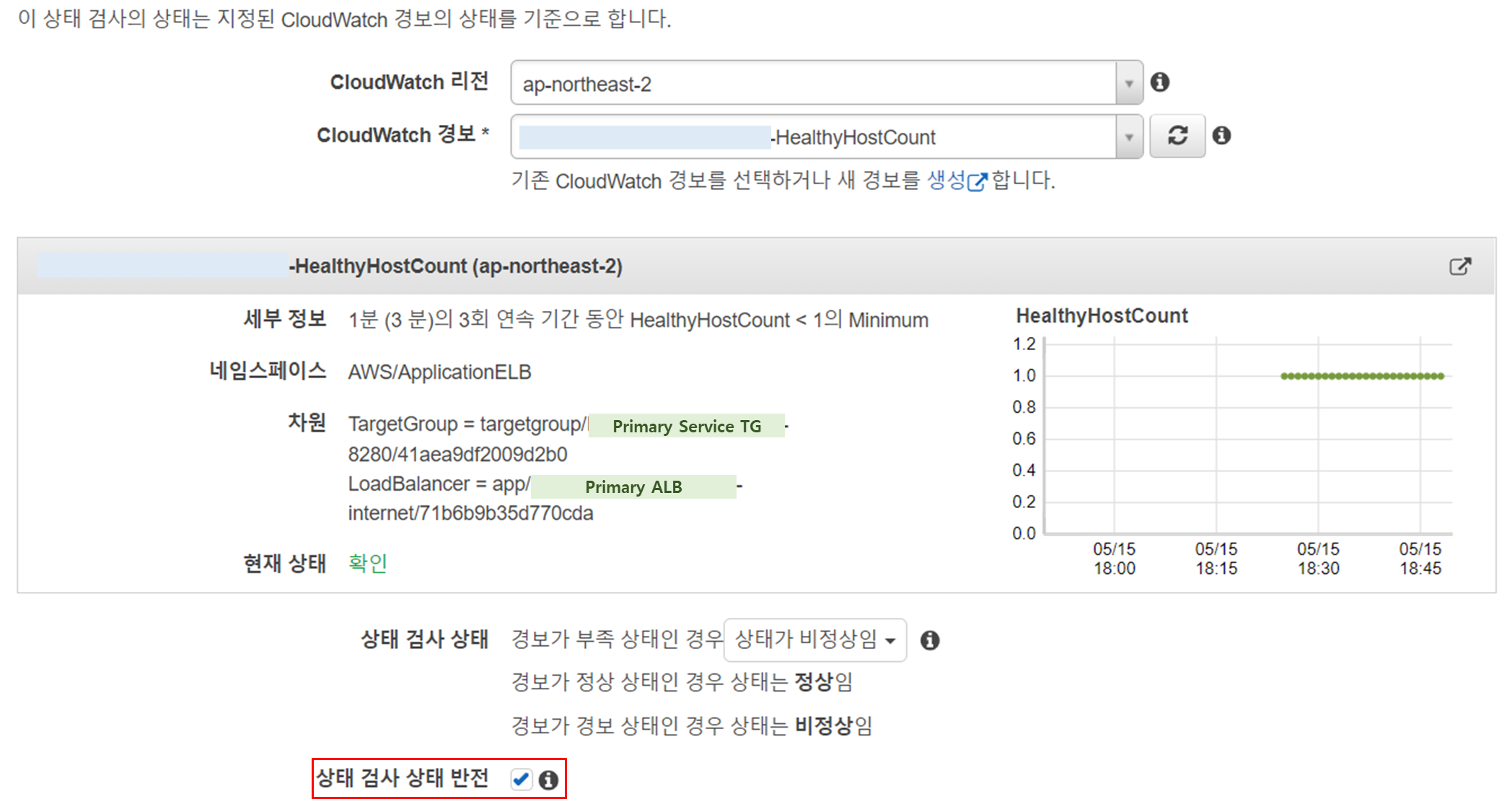
Route53 상태 검사는 앞 단계에서 생성한 CloudWatch Alarm 기반으로 수행되도록 아래와 같이 설정한다.
- 상태 검사 구성
- EndPoint: IP 혹은 DNS 값을 입력하여 해당 리소스 상태에 따라 상태 결정
- 다른 상태 검사 상태: 기존의 Route53 상태 검사 결과에 따라 상태 결정
- CloudWatch 경보 상태: CloudWatch Alarm 경보 상태에 따라 상태 결정
Primary와 Secondary에 대해 CloudWatch 경보 상태를 선택한다.
이때 Secondary는 상태 검사 상태 반전 값을 활성화 한다 (우측 이미지).
이와 같이 설정하는 이유는 Primary의 상태가 정상일 때 Secondary 상태는 비정상, Primary 상태 비정상일 때 Secondary 상태는 정상으로 설정하기 위함이다.
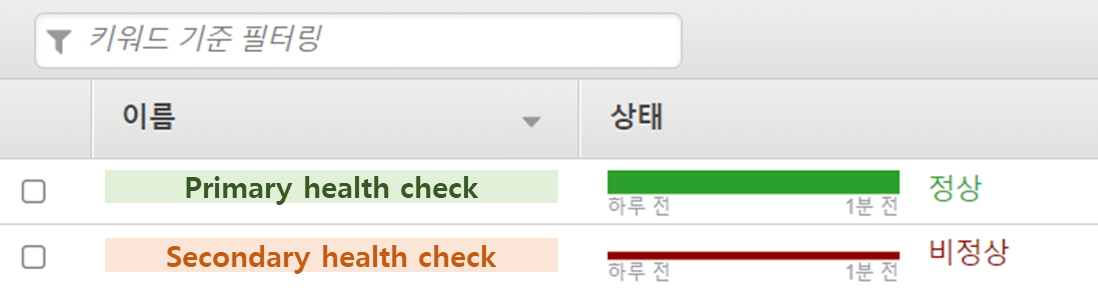
상태 검사 생성이 완료되면 다음과 같이 두 개의 상태 검사가 존재한다.
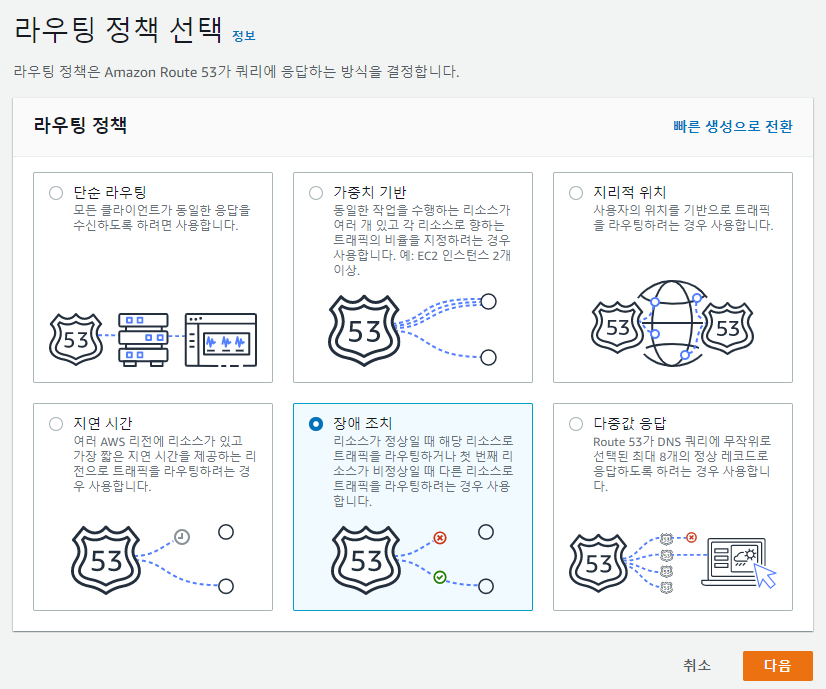
3. Route53 장애조치 레코드 생성
마지막으로 장애조치 레코드를 생성한다.
호스팅 영역에서 레코드 선택시 장애조치 레코드를 쉽게 생성할 수 있도록 다음과 같은 마법사를 제공해준다.
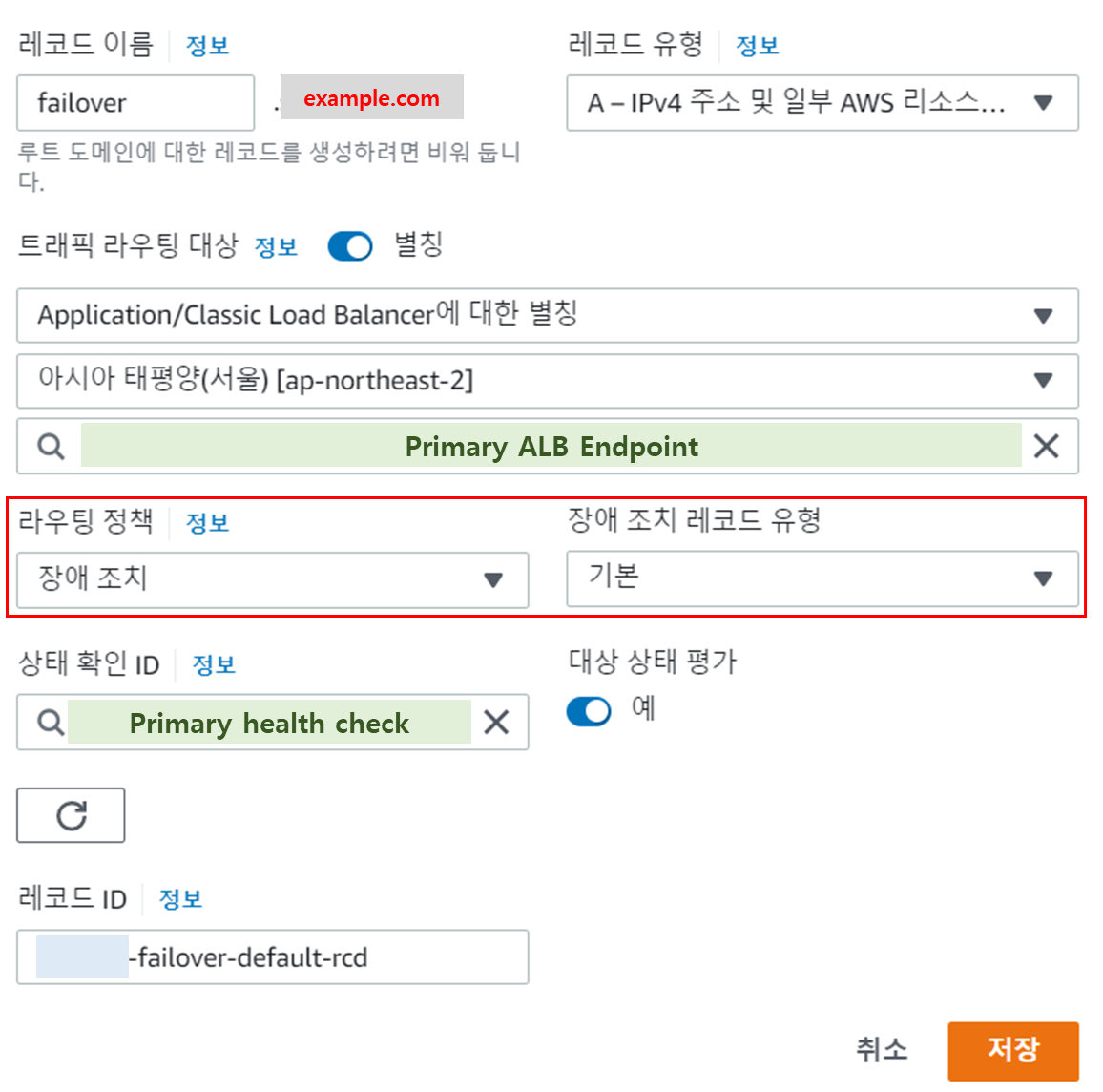
생성이 완료되면 다음과 같이 두 레코드가 생성된다.
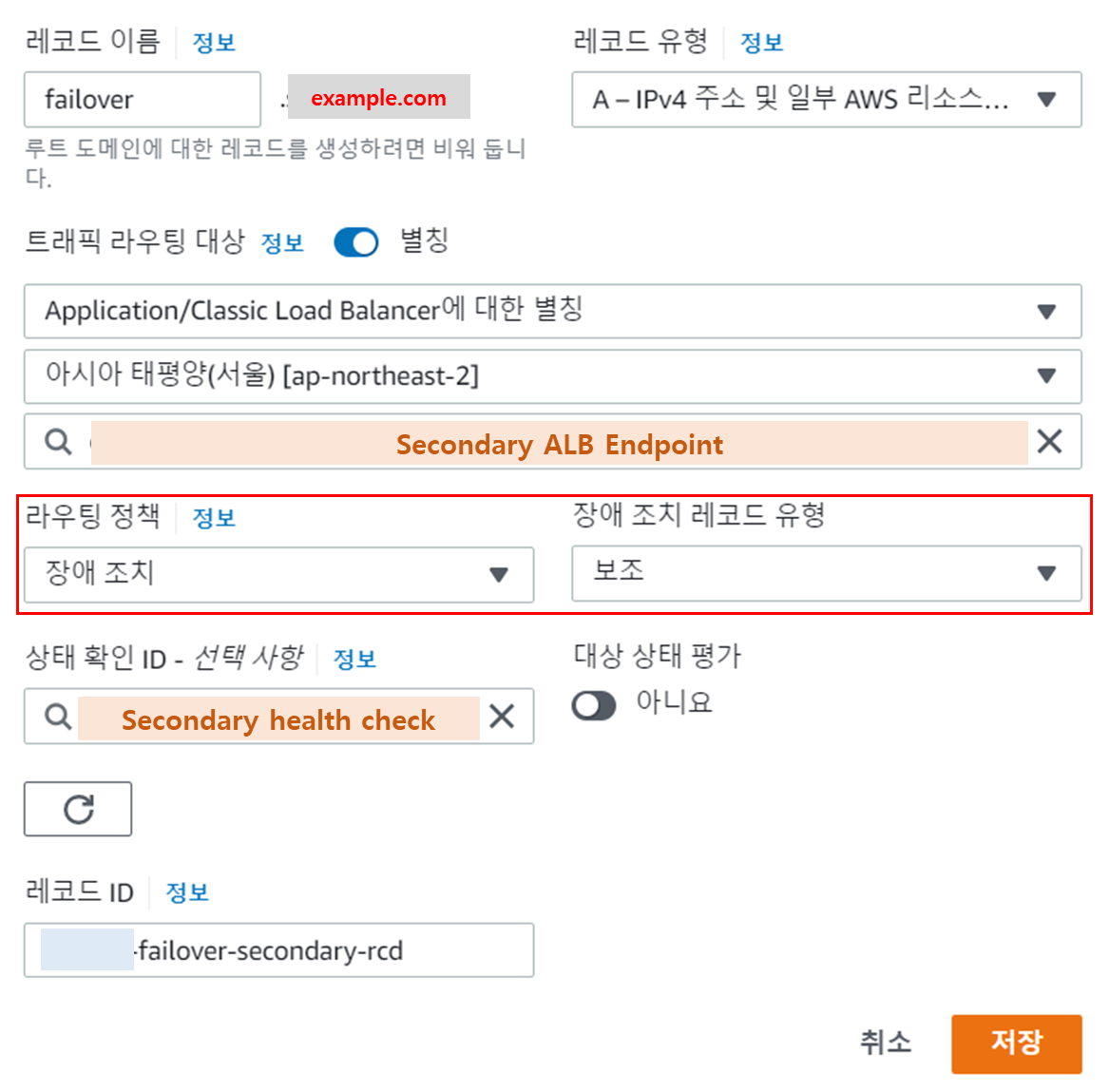
- 레코드이름: 장애조치 레코드를 설정할 레코드 이름 입력 (Primary, Secondary 공통)
- 트래픽 라우팅 대상: 각 ALB 선택
- 라우팅 정책: 장애조치 선택 및 레코드 유형을 Primary - 기본, Secondary - 보조 로 선택
- 상태 확인 ID: 2 단계에서 생성한 health check를 각각 등록
- 레코드 ID: 장애조치 레코드의 경우 동일한 레코드 이름이 사용되므로 각 레코드들을 구분하기 위한 ID

4. 장애조치 테스트
Primary 서비스가 비정상이 될 경우 Secondary 서비스로 잘 전환되는지 확인한다.
4.1 Primary 서비스 확인
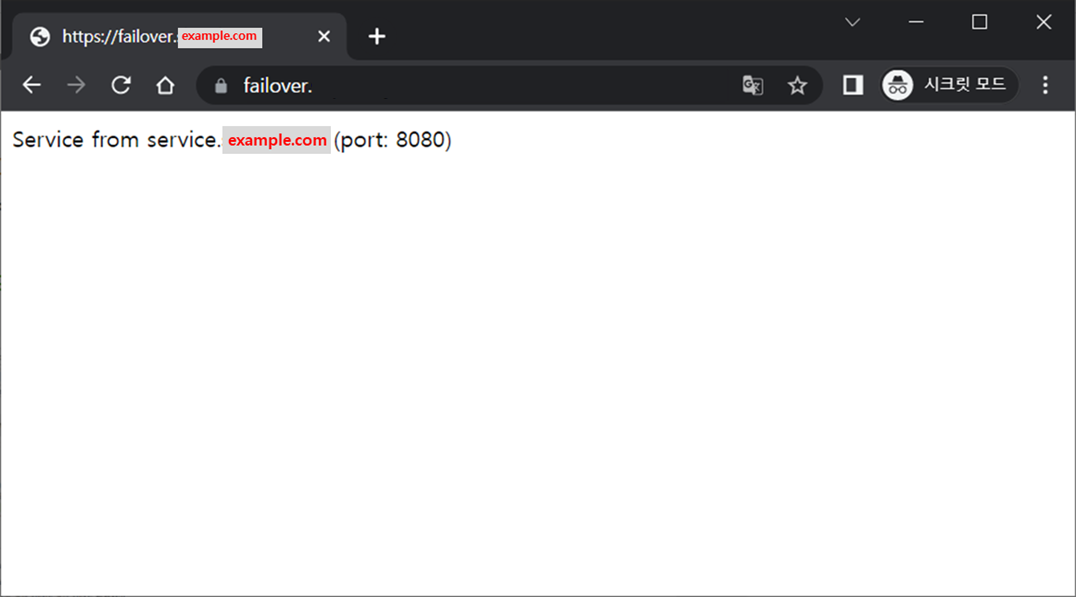
레코드 생성 이후 failover.sbpark.xyz에 대해 요청하면 아래와같이 Primary 서비스가 사용자에게 제공된다.
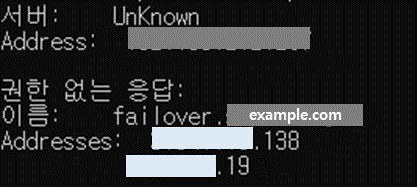
또한, nslookup 명령어를 통해 primary ALB의 IP 확인도 가능하다.
4.2 Primary 서비스 중지
CloudWatch 경보를 생성하기위해 Primary ALB에 연결되어있는 Primary target group의 인스턴스를 임의로 중지한다.

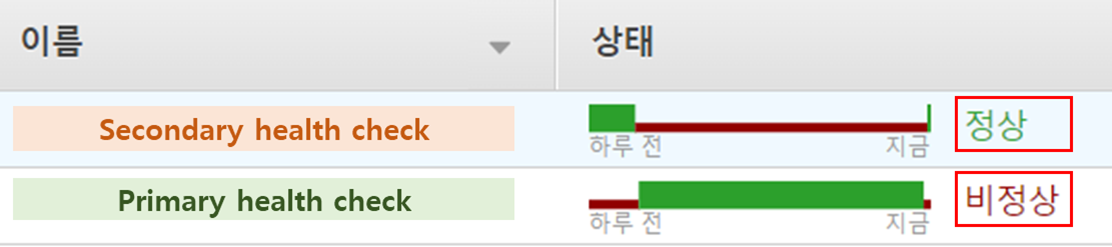
인스턴스 중지 후 CloudWatch Alarm 경보를 대기한다. 이후 Route53 상태 검사를 확인해보면 아래와 같이 Secondary 가 정상, Primary가 비정상 전환된 것을 확인할 수 있다.
동일한 url을 브라우저에 입력하면 secondary alb -> secondary service로 전송되는 것을 확인할 수 있다.
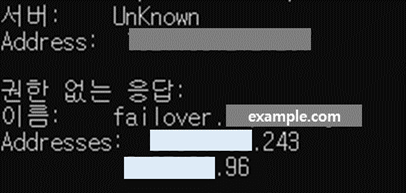
nslookup을 통해 ALB의 IP를 확인해보면 Secondary ALB의 IP임을 확인할 수 있다.
[참조]
https://docs.aws.amazon.com/ko_kr/Route53/latest/DeveloperGuide/dns-failover-configuring.html
'AWS' 카테고리의 다른 글
| [AWS/CloudFront] CloudFront로 S3 컨텐츠 제공하기 - ② CloudFront 대체 도메인 구성 (1) | 2022.03.24 |
|---|---|
| [AWS/CloudFront] CloudFront로 S3 컨텐츠 제공하기 - ① CloudFront 구성 및 동작 확인 (0) | 2022.03.23 |
| [AWS/ECS] ECS 클러스터 구성 및 컨테이너 서비스하기 (0) | 2022.03.09 |
| [AWS] API GateWay로 Lambda를 호출하여 S3의 파일을 SFTP 서버로 데이터 전송하기 (lambda import) (0) | 2022.03.03 |
| [CodeBuild] ECR 업로드시 CodeBuild Role 권한 오류 (0) | 2022.02.08 |




댓글